
March has been productive. The short version is it’s complicated but we’re exploring happily, and adjusting the scope in small ways to help simplify it. Let me summarise the main things we did this month.
Legal workshop
We welcomed two of our advisors—Neil from the Bodleian and Andrea from GLAM e-Lab—to our HQ to get into the nitty gritty of what a 50-year-old Data Lifeboat needs to accommodate.
As we began the conversation, I centred us in the C.A.R.E. Principles and asked that we always keep them in our sights for this work. The main future challenges are settling around the questions of how identity and the right to be forgotten must be expressed, how Flickr account holders can or should be identified, and whether an external name resolver service of some kind could help us. We think we should develop policies for Flickr members (on consent to be in a Data Lifeboat), Data Lifeboat creators (on their obligations as creators), and Dock Operators (an operations manual & obligations for operating a dock). It’s possible there will also be some challenges ahead around database rights, but we don’t know enough yet to give a good update. We’d like a first-take legal framework of the Data Lifeboat system to be an outcome of these first six months.
Privacy & licensing
These are key concepts central to Flickr—privacy and licensing—and we must make sure we do our utmost to respect them in all our work. It would be irresponsible for us to jettison the desires encoded in those settings for our convenience, tempting though that may be. By that I mean, it would be easier for us to make Data Lifeboats that contained whatever photos from whomever, but we must respect the desires of Flickr creators in the creation process.
There are still big and unanswered questions about consent, and how we get millions of Flickr members to agree to participate and give permission to allow their pictures to be put in other people’s Data Lifeboats.
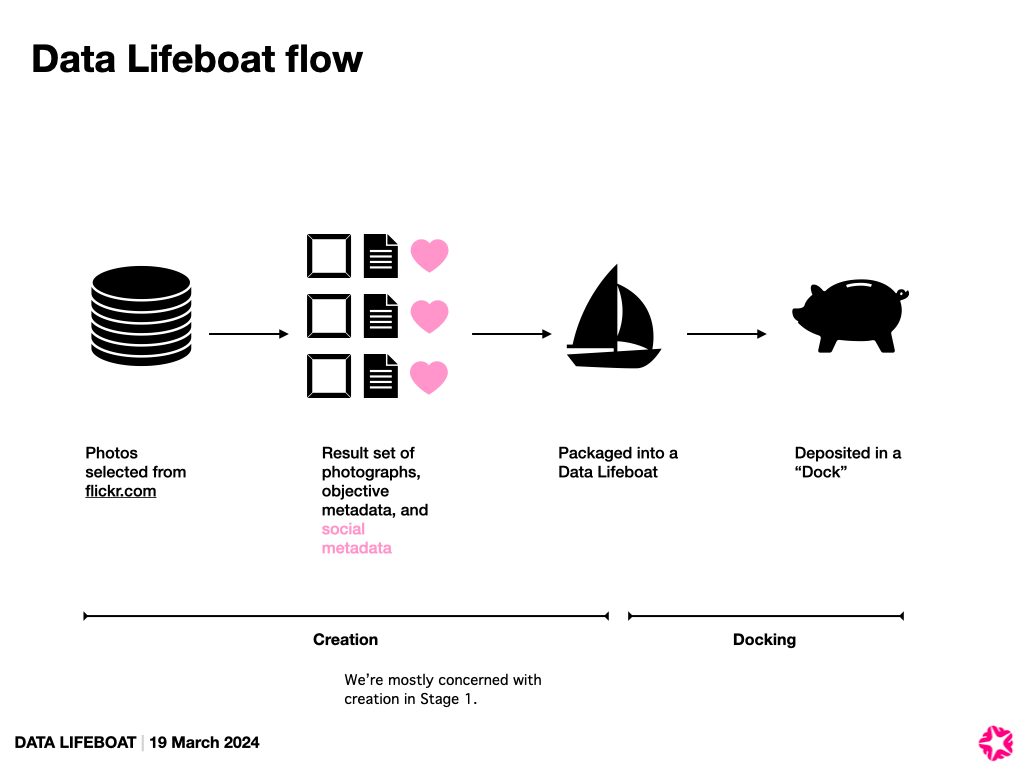
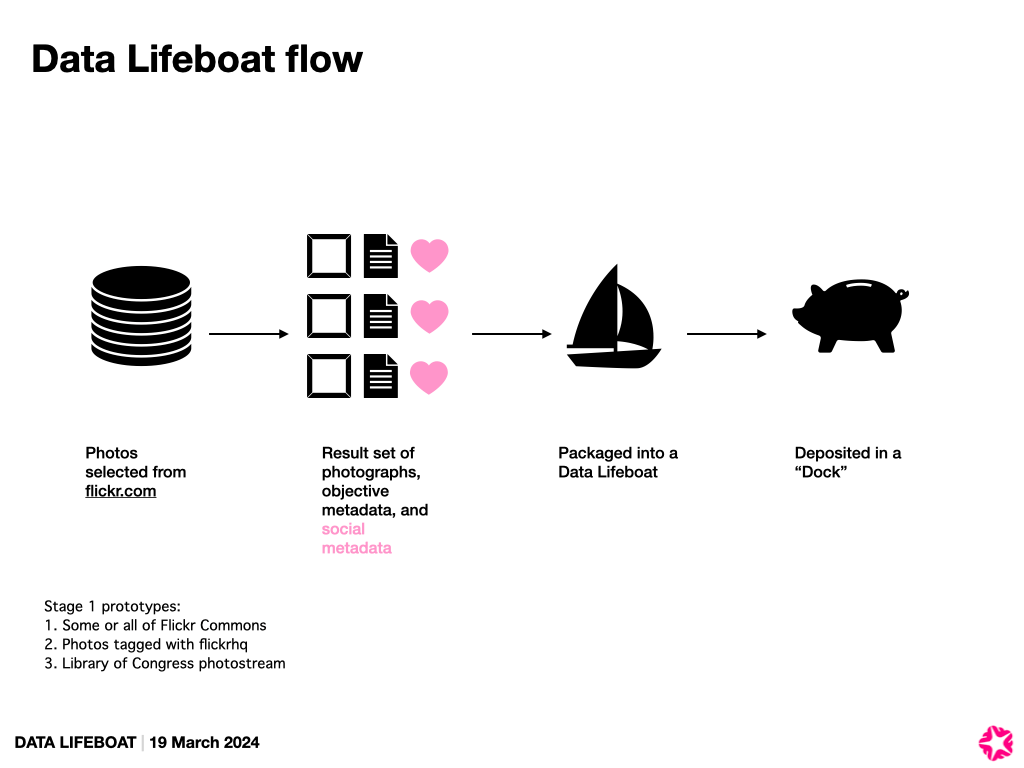
Extending the prototype Data Lifeboat sets
Initially, we had planned to run this 6-month prototype stage with just one test set of images, which would be some or all of the Flickr Commons photographs. But in order to explore the challenges around privacy and licensing, we’ve decided to expand our set of working prototypes to also include the entire Library of Congress Flickr Commons account, and all the photos tagged with “flickrhq” (since that set is something the Flickr Foundation may decide to collect for its own archive and contains photographs from different Flickr members who also happen to have been Flickr staff and would therefore (theoretically) be more sympathetic to the consent question).
Visit to Greenwich
Ewa spotted that there was an exhibition of ambrotype photographic portraits of women in the RNLI at the Maritime Museum in Greenwich at the moment, so we decided to take a day trip to see the portraits and poke around the brilliant museum. We ended up taking a boat from Greenwich to Battersea which was a nice way to experience the Thames (and check out that boat’s life saving capabilities).


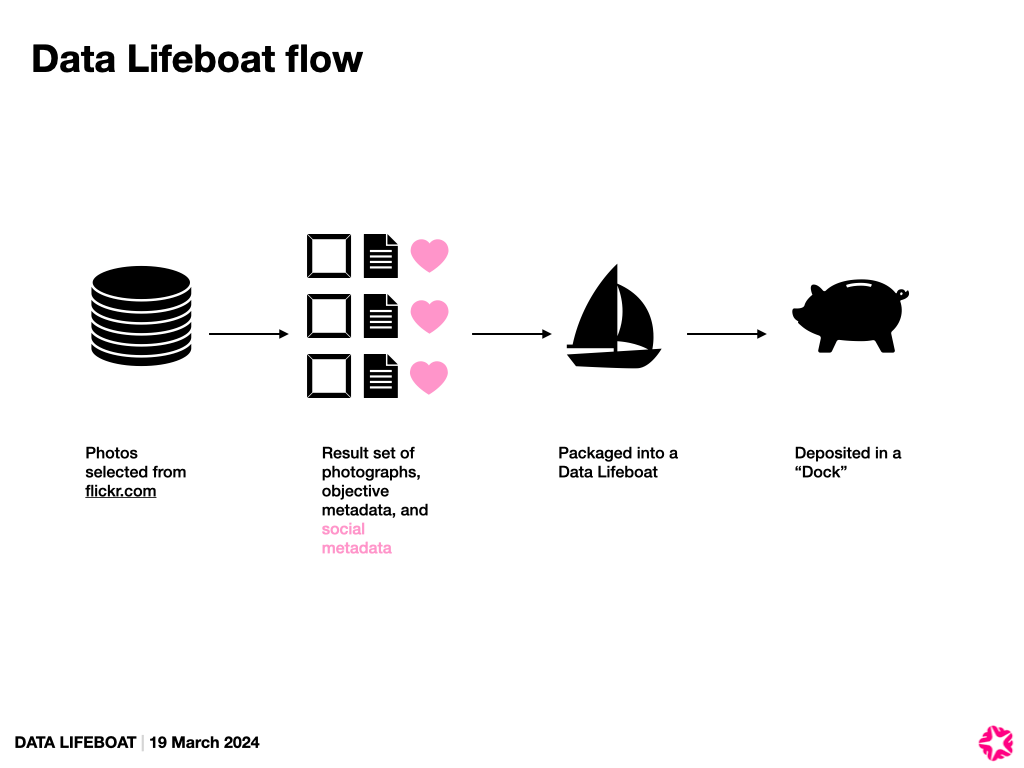
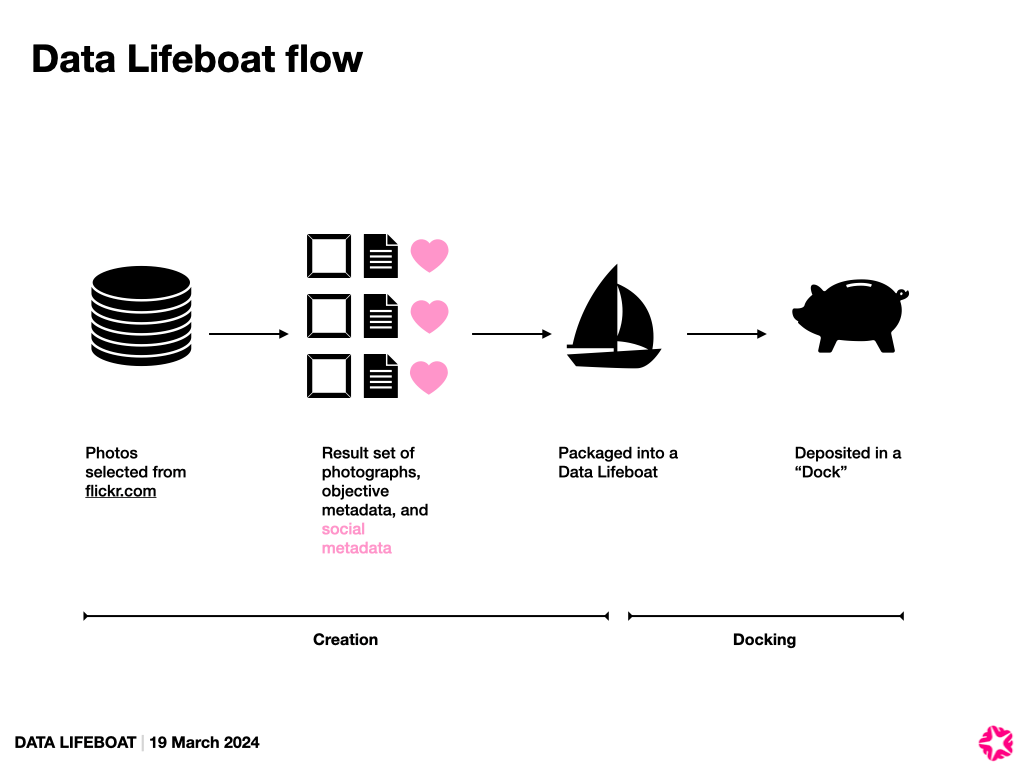
The Data Lifeboat creation process
I found myself needing to start sketching out what it could look like to actually create a Data Lifeboat, and particularly not via a command line, so we spent a while in front of a whiteboard kicking that off.
At this point, we’re imagining a few key steps:
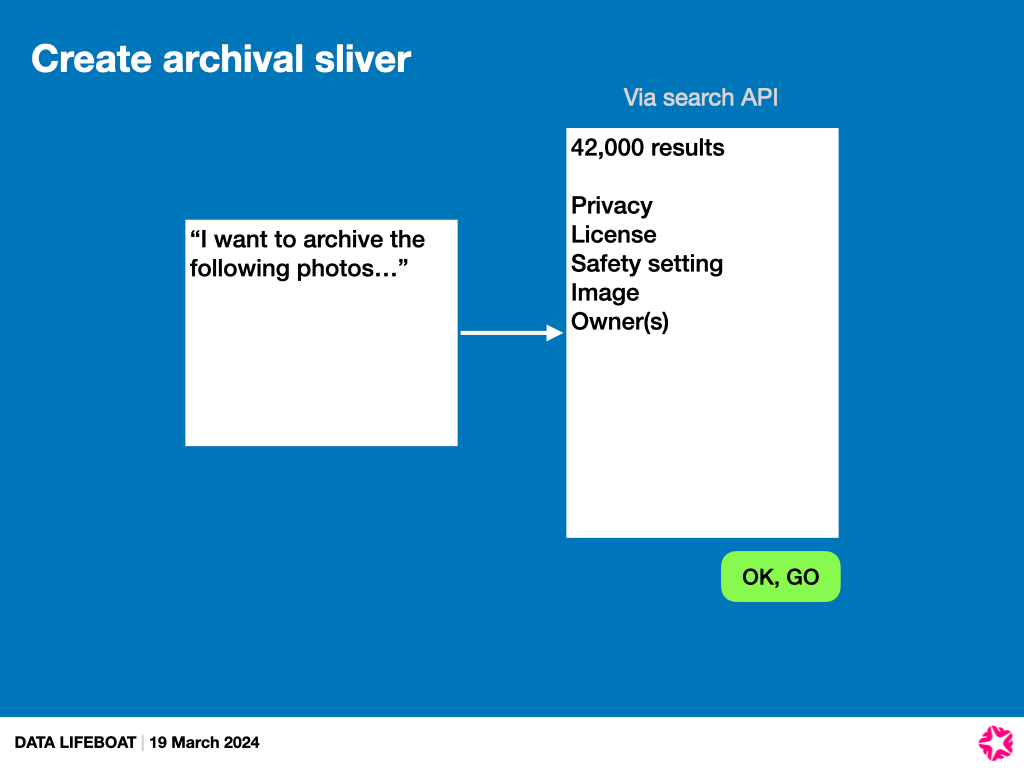
- The Query – “I want these photos” – is like a search. We could borrow from our existing Flinumeratr toy.
- The Results – Show the images, some metadata. But it’s hard to show information about the set in aggregate at this stage, e.g., how many of the contents are licensed in which way. This could form a manifest for the Data Lifeboat..
- Agreement – We think there’s a need for the Data Lifeboat creator to agree to certain terms. Simple, active language that echoes the CARE principles, API ToS, and Flickr Community Guidelines. We think this should also be included in the Data Lifeboat it’s connected with.
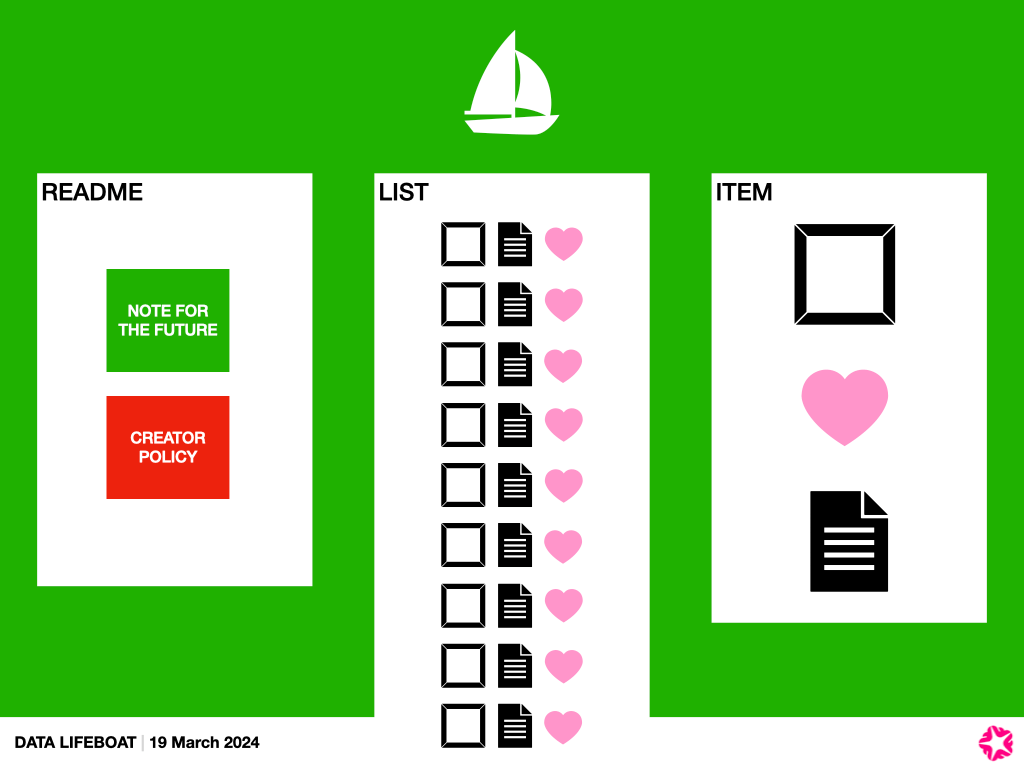
- README / Note to the Future – we love the idea that the Data Lifeboat creator could add a descriptive narrative at this point, about why they are making this lifeboat, and for whom, but we recognised that this may not get done at all, especially if it’s too complicated or time-consuming. This is also a good spot to describe or configure warnings, timers, or other conditions needed for future access. Thanks also to two of our other advisors – Commons members Mary Grace and Alan – who shared with us their organisation’s policies on acquisitions for reference.
- Packaging – This would be asynchronous and invisible to the creator; downloading everything in the background. We realised it could take days, especially if there are lots of Data Lifeboats being made at once.
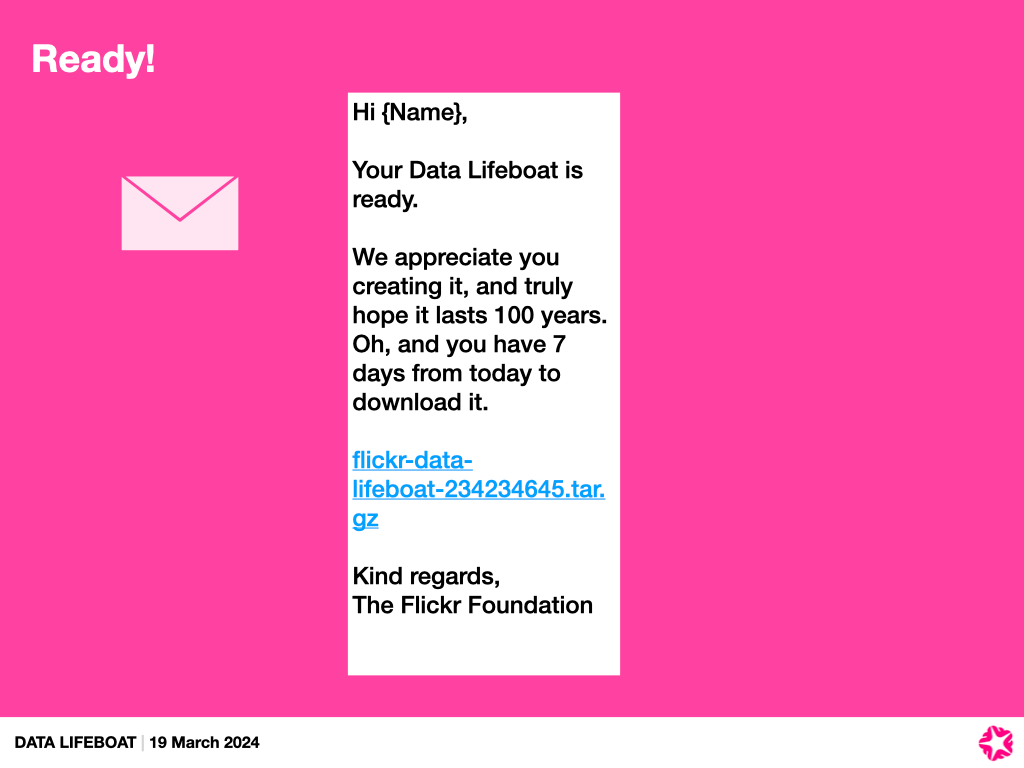
- Ready! – The Data Lifeboat creator gets a note somehow about the Data Lifeboat being ready for download. We may need to consider keeping it available only for a short time(?).
Creation Schematic, 19th March

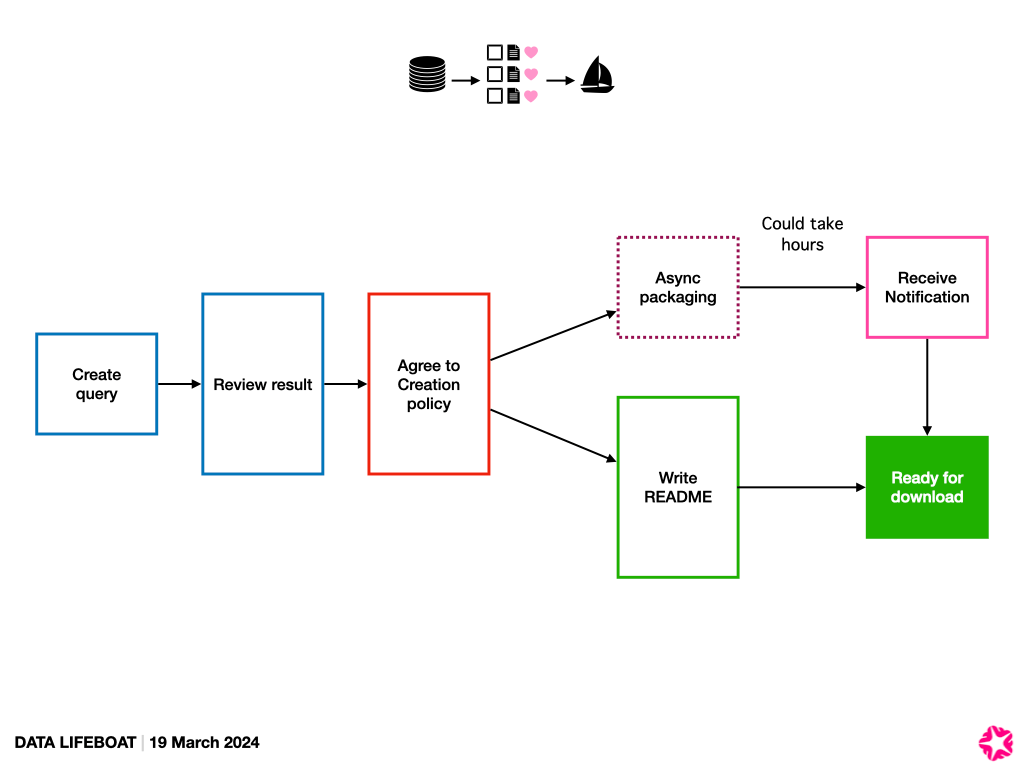




Emergency v Non-Emergency
We keep coming up against this…
The original concept of the Data Lifeboat is a response to the near-death experience that Flickr had in 2017 when its then-owner, Verizon/Yahoo, almost decided to vaporise it because they deemed it too expensive to sell (something known as “the cost of economic divestment”). So, in the event of that kind of emergency, we’d want to try to save as much of this unique collection as possible as quickly as possible, so we’d need a million lifeboats full of pictures created more or less simultaneously or certainly in a relatively short period of time.
In the early days of this work, Alex said that the pressure of this kind of emergency would be the equivalent of being “hugged to death by the archivists,” as we all try— in very caring and responsible ways—to save as much as we can. And then there’s the bazillion-emergency-hits-to-the-API-connection problem—aka the “Thundering Herd” problem—which we do not yet have a solution for, and which is very likely to affect any other social media platforms that may also be curious to explore this concept.
We’re connecting with the Flickr.com team to start discussing how to address this challenge. We’re beginning to think about how emergency selection might work, as well as the present, and future, challenges of establishing the identity of photo subjects and account owners. The millions of lifeboats that would be created would surely need the support of the company to launch if they’re ever needed.
This work is supported by the National Endowment for the Humanities.



