Flickr is a photo-sharing website and has always been about connecting people through photography. It is different from a generic image-hosting service. Flickr Commons, the program launched in 2008 for museums, libraries, and archives to share their photography collections, is different again: it’s about sharing photography collections with a very big audience, and providing tools to help people to contribute information and knowledge about the pictures, ideally to supplement whatever catalogue information already exists.
A collection development policy is a framework for information institutions like libraries, archives and museums to define what they collect, and importantly, what they don’t collect. It’s an important part of maintaining a coherent and valuable collection while trends and technologies change and advance around the organisation. We think it’s time for the Flickr Commons to have a policy like this.
- Please visit the Collection Development Policy, Version 2023.10.01.1 Google doc if you’d like to review it.
As the Flickr Commons collection grows, we’re seeing all kinds of images in there: photographs, maps, documents, drawings, museum objects, book scans, and more. Therefore, one aspect of the policy is to ask our members to use of Flickr’s “Content-Type” field to improve the way their images can be categorised and found in search.
Why are we asking Flickr Commons members to categorise their images?
Since the program launched in 2008, the Flickr Commons has grown to also include illustrations, maps, letters, book scans, and other imagery. The default setting for uploads across all accounts is content_type=Photo, so if you don’t alter that default for new uploads, every image is classified as a photo. This starts to break down if you upload, say, the Engrossed Declaration of Independence, or, a wood engraving of Bloodletting Instruments.
One of the largest Flickr Commons accounts is the great and good British Library, which famously published 1 million illustrations into the program in 2013, announcing:
“The images themselves cover a startling mix of subjects: There are maps, geological diagrams, beautiful illustrations, comical satire, illuminated and decorative letters, colourful illustrations, landscapes, wall-paintings and so much more that even we are not aware of… We are looking for new, inventive ways to navigate, find and display these ‘unseen illustrations’. ”
– A million first steps by Ben O’Steen, 12 December 2013
Because the default setting for uploads is content_type=Photos, it meant that every search on Flickr Commons was inundated with “the beige 19th Century.” Those images had, by default, been categorised as Photos, but instead were millions of pictures from 17th, 18th, and 19th-century books.
Earlier this year, the British Library team adjusted the images in their account to set them as “Illustration/Art” and not Photos. But, that had the effect of “hiding” their content from general, default-set searches. This unintentional hiding raised a little alarm with their followers (who were used to seeing the book scans in their searching), some of whom wrote in to ask what had happened. And rightly so, because it had yet to be explained to them by us or by the search interface.
The Backstory
In any aggregated system of cultural materials, you get colossal variegation. Humans describe things differently, no matter how many professional standards we try to implement. Last year, in 2022, the Flickr Commons was mostly a vast swathe of images from scanned book pages. Not photographs, per se, or things created first as photographs.
There have been two uploads into Flickr Commons of over one million things. The first one was in 2013, by the British Library, whose intention was to ask the community to help describe the million or so book illustrations they had carefully organised with book structure metadata and described using clever machine tags. The BL team was also careful to avoid annoying the Flickr API spirits by carefully pacing their uploading not to cause any alerts. Since then, they have built a community around the collection for over a decade now, cultivating the creative reuse, inspiration and research in the imagery, primarily through the British Library Labs initiative.
The second gigantic upload, in 2014, was (also) mostly images cropped by a computer program. Created by a solo developer working in a Yahoo Research fellowship, the code was run over an extensive collection of content in Internet Archive (IA) book digitization program to crop out images on scanned book pages. Those were shoved into flickr.com using the API. The developer immediately reached the free account limits, so they negotiated through Yahoo senior management that these millions of images should become part of the Flickr Commons program in an Internet Archive Book Images (IABI) account. Since the developer was also loosely associated with the Internet Archive (IA), IA agreed to be the institutional partner in the Flickr Commons. That’s a requirement of joining the program—that the account is held by an organisation, not an individual.
These two uploads utterly overwhelmed the smaller Flickr Commons photography collections, even as the two approaches were so different.
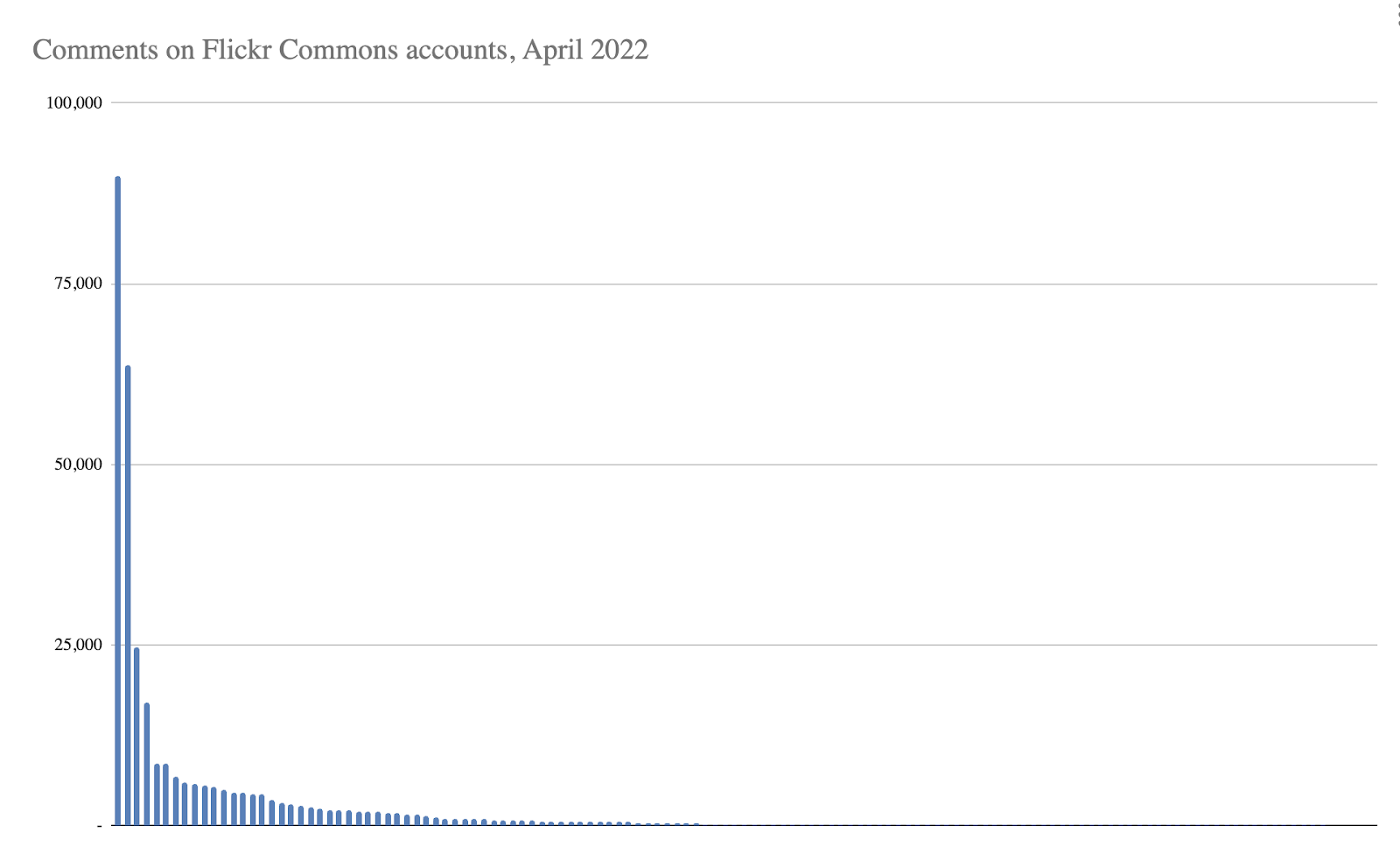
Here’s a graph from April 2022 data that shows all Commons members on the x-axis, and their upload counts on the y-axis.
The IABI account is 5x larger than all the other accounts combined. If you remove the two giants from the data, the average upload per account is just under 3,000 pictures.
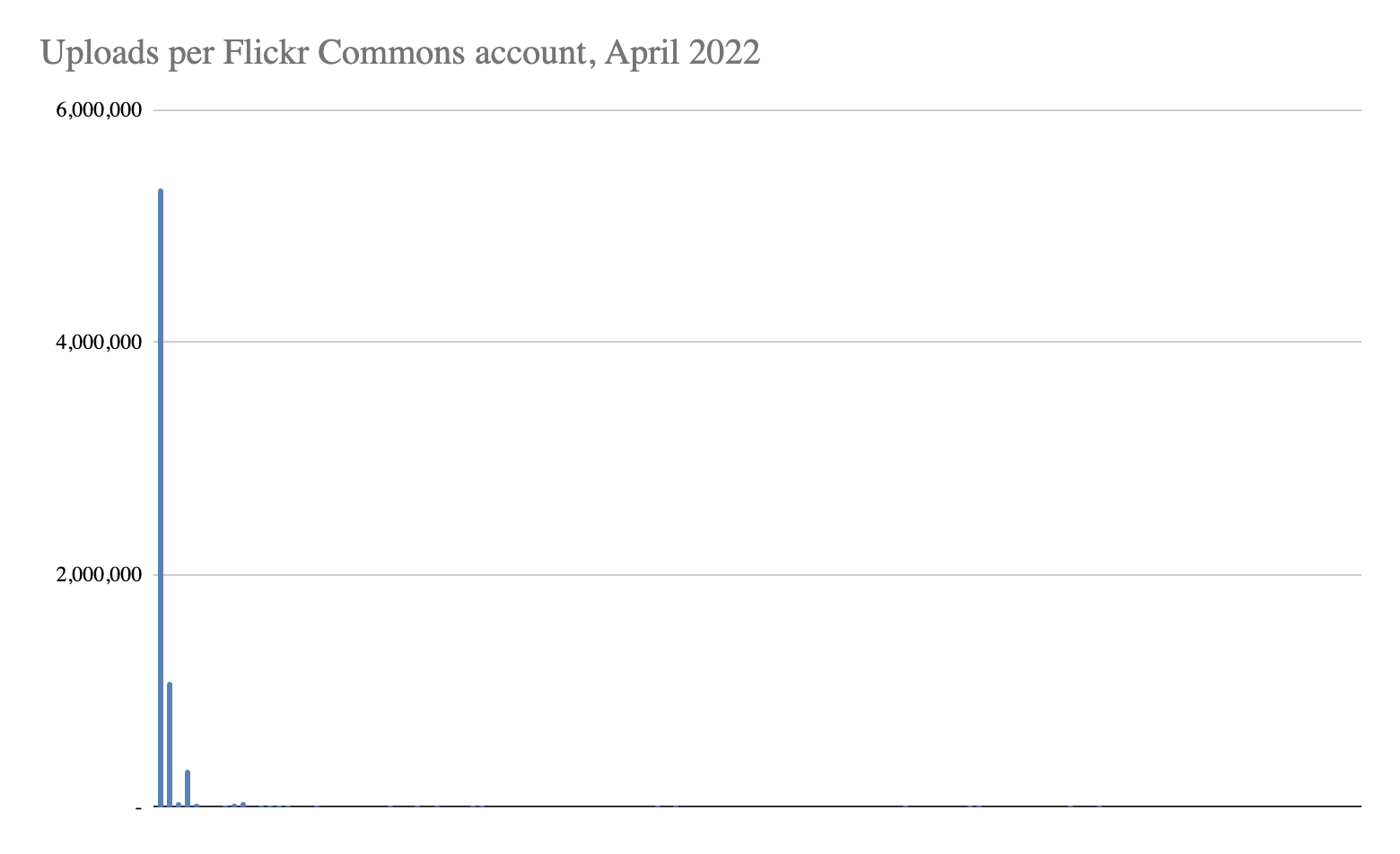
These whopper accounts both have billions of views overall. These view counts are unsurprising, given that they completely dominated all search results in Flickr Commons. While the Flickr Commons’ first goal has always been to “increase public access to photography collections”, its secondary—and in my opinion, much more interesting—goal is to “provide a way for the public to contribute information.”
You can see from the two following graphs that a big photo count doesn’t imply deeper engagement. In fact, we’ve seen the opposite is true, and the Flickr Commons members who enjoy the strongest engagement are those who spend time and effort to engage. Drip-feeding content—and not dumping it all at once—will also help viewers to keep up and get a good view of what is being published.
The fifth account in the most-faved data is the fabulous National Library of Ireland, with about 3,000 photos then, which excels at community engagement, demonstrated by its 181,000 faves.
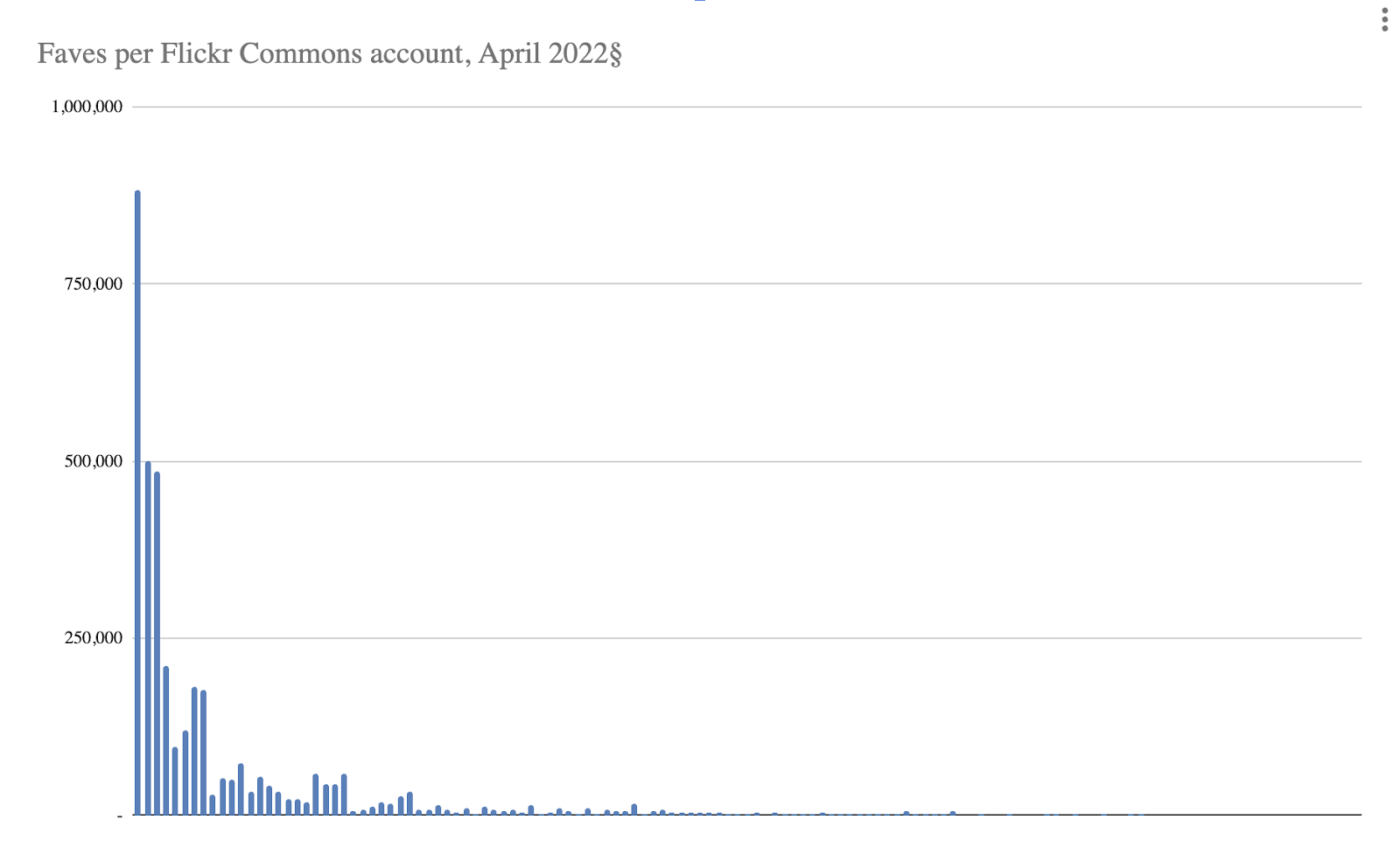
In the comments data, IABI ranks 21st (~3,000), and British Library 27th (~2,000). The top-commented accounts are all in a groove of stellar community engagement.
Employees working in small archives (or large ones, for that matter) simply cannot compete with a content production software program that auto-generates a crop of an image in a book scan and its associated automated many-word metadata. At the Flickr Foundation, we have a place in our hearts for the smaller cultural organisations and want to actively support their online engagements through the Flickr Commons program.
I remember when the IABI account went live. Even though I wasn’t working at Flickr or at the Flickr Foundation at the time, I thought it was a mistake to allow such a vast blast of not-photographs into the Flickr Commons, particularly the second massive collection, mainly because it had been so broadly described, meaning it would turn up content in every search.
Fast forward to last year, in April, when—as my strange first step as Executive Director—I decided in consultation and agreement with the staff at IA to act. We agreed to delete the gargantuan Internet Archive Book Images (IABI) account.
A couple of weeks later, people realised it had happened, and a riot of “Flickr is destroying the public domain” posts popped up. I had not prepared for this reaction, which is the opposite tone I want the Flickr Foundation to set! I’d consulted with the Internet Archive, and a consensus had been reached. But, I was also ignorant of the community enjoying the IABI account—I had presumed there was no community engagement since nobody had logged into the IABI account since just after the giant upload had happened in 2014. That was a mistake, I readily admit, but in my defence, the IA team echoed that same impression when we discussed it. The lone developer (who didn’t work at IA) had uploaded the millions of book images and did not engage with the community. The images were generated from lots of different institutions’ collections digitised through the Internet Archive’s wonderful book scanning initiative. Unfortunately, correct attribution for each institution had not been included in the initial metadata produced for each image. (This was later rectified by a code rewrite by Smithsonian Libraries and Archives, with support from Flickr engineering.) In some cases the content was known to have no copyright—so didn’t fit in the Flickr Commons’ “no known copyright restrictions” assertion and could/should have been declared public domain materials—along with the content_type=Photo declaration, and broad, auto-generated metadata (along with some tagging to group images into their books, for example). In other words, a millions-of-things mess.
Despite my hesitation, we decided to restore the entire account. This scale of restoration is an incredible engineering feat and an indication of the world-class team working behind the scenes at Flickr. We also set the correct content type designation and adjusted the licences on the restored images to CC0 as Internet Archive does not claim any rights for them. This has the benefit of making them more clearly classified for reuse.
What we are doing about it
We need to be more restrained when it comes to digital commonses. These huge piles of stuff sound great, but they are not often made with care by people. They’re generated en masse by computers and thrown online. (As a related aside, look to the millions of licensed pieces of content that are mined and inhaled to improve AI programs as their licences are ignored.)
The British Library acknowledged this, asking for interaction and effort from interested people, and stated explicitly that their 1 million images were “wholly uncurated.” People ultimately enjoyed hunting around in a millions-of-things pile for illustrations of things and made some beautiful responses to them. Indeed, one person managed to add 45,000 tags to the British Library’s Flickr Commons content. 45,000!
Perhaps I’m about to contradict myself again and say this scale of access at a base level was good, at least for computers and computation. But, it wasn’t good inside the Flickr Commons program, and that’s why we need the Collection Development Policy so we can encourage and nurture the seeing, enjoyment and contributions to our shared photographic history we always wanted.
And that’s why we’re drafting the new policy in collaboration with the membership, so we can help Flickr Commons members know how to hold the shape of the container we’ve created instead of bursting it.
With thanks to Josh Hadro, Martin Kalfatovic, Nora McGregor, Mia Ridge, Alexis Rossi, and Jessamyn West for your time and feedback on this post.