Eryk Salvaggio is a 2024 Flickr Foundation Research Fellow, diving into the relationships between images, their archives, and datasets through a creative research lens. This three-part series focuses on the ways archives such as Flickr can shape the outputs of generative AI in ways akin to a haunting. Read part one, or continue to part three.

“Today the photograph has transformed again.” – David A. Shamma, in a blog post announcing the YFCC100M dataset.
In part one of this series, I wrote about the differences between archives, datasets, and infrastructures. We explored the movement of images into archives through the simple act of sharing a photograph in an online showcase. We looked at the transmutation of archives into datasets — the ways those archives, composed of individual images, become a category unto themselves, and analyzed as an object of much larger scale. Once an archive becomes a dataset, seeing its contents as individual pieces, each with its own story and value, requires a special commitment to archival practices.
Flickr is an archive — a living and historical record of images taken by people living in the 21st century, a repository for visual culture and cultural heritage. It is also a dataset: the vast sum of this data, framed as an overwhelming challenge for organizing, sorting, and contextualizing what it contains. That data becomes AI infrastructure, as datasets made to aid the understanding of the archive become used in unexpected and unanticipated ways.
In this post, I shift my analysis from image to archive to dataset, and trace the path of images as they become AI infrastructure — particularly in the field of data-driven machine learning and computer vision. I’ll again turn to the Flickr archive and datasets derived from it.
99.2 Million Rows
A key case study is a collection of millions of images shared in June 2014. That’s when Yahoo! Labs released the YFCC100M dataset, which contained 99.2 million rows of metadata describing photos by 578,268 Flickr members, all uploaded to Flickr between 2004 and 2014 and tagged with a CC license. The dataset contained information such as photo IDs, URLs, and a handful of metadata such as the title, tags, description. I believe that the YFCC100M release was emblematic of a shift in the public’s — and Silicon Valley’s — perception of the visual archive into the category of “image datasets.”
Certainly, it wasn’t the first image dataset. Digital images had been collected into digital databases for decades, usually for the task of training image recognition systems, whether for handwriting, faces, or object detection. Many of these assembled similar images, such as Stanford’s dogs dataset or NVIDIA’s collection of faces. Nor was it the first transition that a curated archive made into the language of “datasets.” For example, the Tate Modern introduced a dataset of 70,000 digitized artworks in 2013.
What made YFCC100M interesting was that it was so big, but also diverse. That is, it wasn’t a pre-assembled dataset of specific categories, it was an assortment of styles, subject matter, and formats. Flickr was not a cultural heritage institution but a social media network with a user base that had uploaded far more images than the world’s largest libraries, archives, or museums. In terms of pure photography, no institution could compete on scale and community engagement.
The YFCC100M includes the description, tags, geotags, camera types, and links to 100 million source images. As a result, we see YFCC100M appear over and over again in papers about image recognition, and then image synthesis. It has been used to train, test, or calibrate countless machine vision projects, including high-rated image labeling systems at Google and OpenAI’s CLIP, which was essential to building DALL-E. Its influence in these systems rivals that of ImageNet, a dataset of 14 million images which was used as a benchmark for image recognition systems, though Nicolas Maleve notes that nearly half of ImageNet’s photos came from Flickr URLs. (ImageNet has been explored in-depth by Kate Crawford and Trevor Paglen.)
10,000 Images of San Francisco
It is always interesting to go in and look at the contents of a dataset, and I’m often surprised how rarely people do this. Whenever we dive into the actual content of datasets we discover interesting things. The YFCC100M dataset contains references to 200,000 images by photographer Andy Nystrom alone, a prolific street photographer who has posted nearly 8 million images to Flickr since creating their account in 2008.
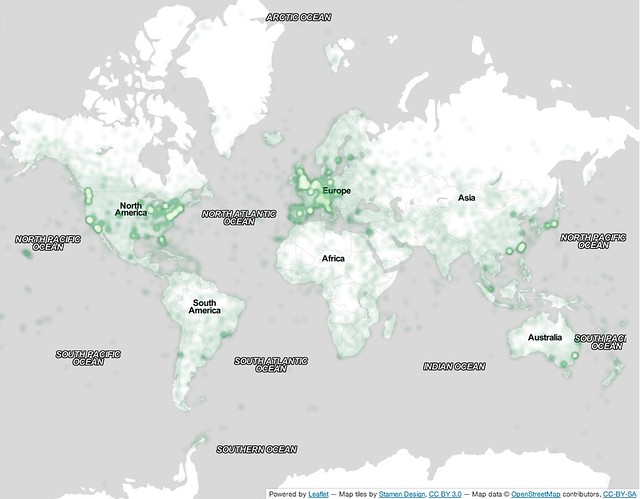
The dataset contains more than 10,000 images each of London, Paris, Tokyo, New York, San Francisco, and Hong Kong, which outnumber those of other cities. Note the gaps here: all cities of the Northern hemisphere. When I ask Midjourney for an image of a city, I see traces of these locations in the output.

Are these strange hybrids a result of the prevalence of Flickr in the calibration and testing of these systems? Are they a bias accumulated through the longevity of these datasets and their embeddedness into AI infrastructures? I’m not confident enough to say for sure. But missing from the images produced from the generic prompt “city” are traces of what Midjourney considers an African city. What emerges are not shiny, glistening postcard shots or images that would be plastered on posters by the tourist bureau. Instead, they seem to affirm the worst of the colonizing imagination: unpaved roads, cars broken down in the street. The images for “city” are full of windows reflecting streaks of sunlight; for “African city,” these are windows absent of glass.
“A prompt about a ‘building in Dakar’ will likely return a deserted field with a dilapidated building while Dakar is a vibrant city with a rich architectural history,” notes the Senegalese curator Linda Dounia. She adds: “For a technology that was developed in our times, it feels like A.I. has missed an opportunity to learn from the fraught legacies that older industries are struggling to untangle themselves from.”

Beyond the training data, these legacies are also entangled in digital infrastructures. We know images from Flickr have come to shape the way computers represent the world, and how we define tests of AI-generated output as “realistic.” These definitions emerge from data, but also from infrastructures of AI. Here, one might ask if the process of calibrating images to places has been so centered on the geographic regions where Flickr has access to ample images: 10,000 images each from cities of the Northern Hemisphere. These created categories for future assessment and comparison.
What we see in those images of an “African city” are what we don’t see in the data set. What we see is what is what is missing from that infrastructure: 10,000 pictures of Lagos or Nairobi. When these images are absent from the training data, they influence the result. When they are absent from the classifiers and calibration tools, that absence is entrenched.
The sociologist Avery Gordon writes of ghosts, too. For Gordon, the ghost, or the haunting, is “the intermingling of fact, fiction and desire as it shapes the personal and social memory … what does the ghost say as it speaks, barely, in the interstices of the visible and invisible?” In these images, the ghost is the image not taken, the history not preserved, the gaps that haunt the archives. It’s clear these absences move into the data, too, and that the images of artificial intelligence are haunted by them, conjuring up images that reveal these gaps, if we can attune ourselves to see them.
There is a limit to this kind of visual infrastructural analysis of image generation tools — its reliance on intuition. There is always a distance between these representations of reality in the generated image and the reality represented in the datasets. Hence our language of the seance. It is a way of poking through the uncanny, to see if we can find its source, however remote the possibility may be.
Representativeness
We do know a few things, in fact. We know this dataset was tested for representativeness, that was defined as how evenly it aligned with Flickr’s overall content — not the world at large. We know, then, that the dataset was meant to represent the broader content of Flickr as a whole, and that the biases of the dataset — such as the strong presence of these particular cities — are therefore the biases of Flickr. In 2024, an era where images have been scraped from the web wholesale for training data without warning or permission, we can ask if the YFCC100M dataset reflected the biases we see in tools like DALL-E and Midjourney. We can also ask if the dataset, in becoming a tool for measuring and calibrating these systems, may have shaped those biases as a piece of data infrastructure.
As biased data becomes a piece of automated infrastructure, we see biases come into play from factors beyond just the weights of the training data. It also comes into play in the ways the system maps words to images, sorts out and rejects useful images, and more. One of the ways YFCC100M’s influence may shape these outcomes is through its role in training the OpenAI tool I mentioned earlier, called CLIP.
CLIP looks at patterns of pixels in an image and compares them to labels for similar sets of pixels. It’s a bridge that connects the descriptions of images to words of a user’s prompt. CLIP is a core connection point between words and images within generative AI. Recognizing whether an image resembles a set of words is how researchers decided what images to include in training datasets such as LAION 5B.
Calibration
CLIP’s training and calibration dataset contained a subset of YFCC100M, about 15 million images out of CLIP’s 400 million total. But CLIP was calibrated with, and its results tested against, classifications using YFCC100M’s full set. By training and calibrating CLIP against YFCC100M, that dataset played a role in establishing the “ground truth” that shaped CLIP’s ability to link images to text.
CLIP was assessed on its ability to scale the classifications produced by YFCC100M and MS-COCO, another dataset which consisted entirely of images downloaded from Flickr. The result is that the logic of Flickr users and tagging has become deeply embedded into the fabric of image synthesis. The captions created by Flickr members modeled — and then shaped — the ways images of all kinds would be labeled in the future. In turn, that structured the ways machines determined the accuracy of those labels. If we want to look at the infrastructural influences of these digital “ghosts in the machine,” then the age, ubiquity, and openness of the YFCC100M dataset suggests it has a subtle but important role to play in the way images are produced by diffusion models.
We might ask about “dataset bias,” a form of bias that doesn’t refer to the dataset, or the archive, or the images they contain. Instead, it’s a bias introduced through the simple act of calling something a dataset, rather than acknowledging its constitutive pieces. This shift in focus shifts our relationship to these pieces, asking us to look at the whole. Might the idea of a “dataset” bias us from the outset toward ignoring context, and distract us from our obligation of care to the material it contains?

From Drips Comes the Deluge
The YFCC100M dataset was paired with a paper, YFCC100M: The New Data in Multimedia Research, which focused on the needs of managing visual archives at scale. YFCC100M was structured as an index of the archive: a tool for generating insight about what the website held. The authors hoped it might be used to create tools for handling an exponential tide of visual information, rather than developing tools that contributed to the onslaught.
The words “generative AI” never appear in the paper. It would have been difficult, in 2014, to anticipate that such datasets would be seen through a fundamental shift from “index” to “content” for image generation tools. That is a shift driven by the mindset of AI companies that rose to prominence years later.
In looking at the YFCC100M dataset and paper, I was struck by the difference between the problems it was established to address and the eventual, mainstream use of the dataset. Yahoo! released the paper in response to the problems of proprietary datasets, which they claimed were hampering replication across research efforts. The limits on the reuse of datasets also meant that researchers had to gather their own training data, which was a time consuming and expensive process. This is what made the data valuable enough to protect in the first place — an interesting historical counterpoint to today’s paradoxical claim by AI companies that image data is both rare and ubiquitous, essential but worth very little.
Attribution
Creative Commons licensed pictures were selected for inclusion in order to facilitate the widest possible range of uses, noting that they were providing “a public dataset with clearly marked licenses that do not overly impose restrictions on how the data is used” (2). Only a third of the images in the dataset were marked as appropriate for commercial use, and 17% required only attribution. But, in accordance with the terms of the Creative Commons licenses used, every image in the dataset required attribution of some kind. When the dataset was shared with the public, it was assumed that researchers would use the dataset to determine how to use the images contained within it, picking images that complied with their own experiments.
The authors of the paper acknowledge that archives are growing beyond our ability to parse them as archivists. But they also acknowledge Flickr as an archive, that is, a site of memory:
“Beyond archived collections, the photostreams of individuals represent many facets of recorded visual information, from remembering moments and storytelling to social communication and self-identity [19]. This presents a grand challenge of sensemaking and understanding digital archives from non-homogeneous sources. Photographers and curators alike have contributed to the larger collection of Creative Commons images, yet little is known on how such archives will be navigated and retrieved, or how new information can be discovered therein.”
Despite this, there was a curious contradiction in the way Yahoo! Labs structured the release of the dataset. The least restrictive license in the dataset is CC-BY — images where the license requires attribution. Nearly 68 million out of the 100 million images in the dataset specifically stated there could be no commercial use of their images. Yet, the dataset itself was then released without any restrictions at all, described as “publicly and freely usable.”
The dataset of YFCC100M wasn’t the images themselves. It was the list of images, a sample of the larger archive that was made referenceable as a way to encourage researchers to make sense of the scale of image hosting platforms. The strange disconnect between boldly declaring the contents as CC-licensed, while making them available to researchers to violate those licenses, is perhaps evident only in hindsight.
Publicly Available
It may not have been a deliberate violation of boundaries so much as it was a failure to grapple with the ways boundaries might be transgressed. The paper, then, serves as a unique time capsule for understanding the logic of datasets as descriptions of things, to the understanding of datasets as the collection of things themselves. This was a logic that we can see carried out in the relationships that AI companies have to the data they use. These companies see the datasets as markedly different from the images that the data refers to, suggesting that they have the right to use datasets of images under “fair use” rules that apply to data, but not to intellectual property.
This breaks with the early days of datafication and machine learning, which made clearer distinctions between the description of an archive and the archive itself. When Stability AI used LAION 5B as a set of pointers to consumable content, this relationship between description and content collapsed. What was a list of image URLs and the text describing what would be found there became pointers to training data. The context was never considered.
That collapse is the result of a set of a fairly recent set of beliefs about the world which increasingly sees the “image” as an assemblage of color information paired with technical metadata. We hear echoes of this in the defense of AI companies, that their training data is “publicly available,” a term with no actual, specific meaning. OpenAI says that CLIP was trained on “text–image pairs that are already publicly available” in its white paper.
In releasing the dataset, Yahoo’s researchers may have contributed to a shift: from understanding online platforms through the lens of archives, into understanding them as data sources to be plundered. Luckily, it’s not too late to reassert this distinction. Visual culture, memory, and history can be preserved through a return to the original mission of data science and machine learning in the digital humanities. We need to make sense of a growing number of images, which means preserving and encouraging new contexts and relationships between images rather than replacing them with context-free abstractions produced by diffusion models.
Generative AI is a product of datasets and machine learning and digital humanities research. But in the past ten years, data about images and the images themselves have become increasingly interchangeable. Datasets were built to preserve and study metadata about images. But now, the metadata is stripped away, aside from the URL, which is used to analyze an image. The image is translated into abstracted information, ignoring where these images came from and the meaning – and relationships of power – that are embedded into what they depict. In erasing these sources, we lose insight into what they mean and how they should be understood: whether an image of a city was taken by a tourism board or an aid agency, for example. The biases that result from these absences are made clear.
Correcting these biases requires care and attention. It requires pathways for intervention and critical thinking about where images are sourced. It means prioritizing context over convenience. Without attention to context, correcting the source biases are far more challenging.

Data Casts Shadows
In my fellowship with the Flickr Foundation, I am continuing my practice with AI, looking at the gaps between archives and data, and data and infrastructures, through the lens of an archivist. It is a creative research approach that examines how translations of translations shape the world. I am deliberately relying on the language of intuition — ghosts, hauntings, the ritual of the seance — to encourage a more human-scaled, intuitive relationship to this information. It’s a rebuttal of the idea that history, documentation, images and media can be reduced to objective data.
That means examining the emerging infrastructure built on top of data, and returning to the archival view to see what was erased and what remains. What are the images in this dataset? What do they show us, and what do they mean? Maleve writes that to become AI infrastructure, a Flickr image is pulled from the context of its original circulation, losing currency. It is relabeled by machines, and even the associations of metadata itself become superfluous to the goal of image alignment. All that matters is what the machine sees and how it compares to similar images. The result is a calibration: the creation of a category. The original image is discarded, but the residue of whatever was learned lingers in the system.
While writing this piece, I became transfixed by shadows within synthetic images. Where does the shadow cast in an AI generated image come from? They don’t come from the sun, because there is no sunlight within the black box of the AI system. Despite the hype, these models do not understand the physics of light, but merely produce traces of light abstracted from other sources.
Unlike photographic evidence, synthetic photographs don’t rely on being present to the world of light bouncing from objects onto film or sensors. The shadows we see in an AI generated image are the shadows cast by other images. The generated image is itself a shadow of shadows, a distortion of a distortion of light. The world depicted in the synthetic image is always limited to the worlds pre-arranged by the eyes of countless photographers. Those arrangements are further extended and mediated as these data shadows stretch across datasets, calibration systems, engineering decisions, design choices and automated processes that ignore or obscure their presence.
Working Backward from the Ghost
When we don’t know the source of decisions made about the system, the result is unexplainable, mysterious, spooky. But image generation platforms are a series of systems stacked on top of one another, trained on hastily assembled stews of image data. The outcomes go through multiple steps of analysis and calibration, outputs of one machine fed into another. Most of these systems are built upon a subset of human decisions scaled to cover inhuman amounts of information. Once automated, these decisions become disembodied, influencing the results.
In part 3 – the conclusion of this series – I’ll examine a means of reading AI generated images through the lens of power, hoping to reveal the intricate entanglement of context, control, and shifting meanings within text and image pairs. Just as shadows move across the AI generated image, so too, I propose, does the gaze of power contained within the archives.
I’ll attempt to trace the flow of power and meaning through datasets and data infrastructures that produce these prompted images, working backwards from what is produced. Where do these training images come from? What stories and images do they contain, or lack? In some ways, it is impossible to parse, like a ghost whose message from the past is buried in cryptic riddles. A seance is rarely satisfying, and shadows disappear under a flashlight.
But it’s my hope that learning to read and uncover these relationships improves our literacy about so-called AI images, and how we relate to them beyond toys for computer art. Rather, I hope to show that these are systems that perpetuate power, through inclusion and exclusion, and the sorting logic of automated computation. The more we automate a system, the more the system is haunted by unseen decisions. I hope to excavate the context of decisions embedded within the system and examine the ways that power moves through it. Otherwise, the future of AI will be dictated by what can most easily be forgotten.
Read part three here.
***
I would be remiss not to point to the excellent and abundant work on Flickr as a dataset that has been published by Katrina Sluis and Nicolas Malevé, whose work is cited here but merits a special thank you in shaping the thinking throughout this research project. I am also grateful to scholars such as Timnit Gebru, whose work on dataset auditing has deeply informed this work, and to Dr. Abeba Birhane, whose work on the content of the LAION 5B dataset has inspired this creative research practice.
In the images accompanying this text, I’ve paired images created in Stable Diffusion 1.6 for the prompt “Flickr.com street shadows.” They’re paired with images from actual Flickr members. I did not train AI on these photos, nor did I reference the originals in my prompts. But by pairing the two, we can see the ways that the original Flickr photos might have formed the hazy structures of those generated by Stable Diffusion.